SQL : Windows function

Introduction
La modélisation de données est importante, c'est une composante qui réduit la dette technique de notre data warehouse et permet d'avoir un accès plus simple aux données.
Une fois les données accessibles, les stakeholders commenceront à demander des analyses et des rapports qui seront alimentés par SQL.
Dans un premier temps, le SQL usuel sera utilisé, mais avec le temps, il faudra creuser davantage les données pour pouvoir extraire des informations qui permettront de créer de la valeur.
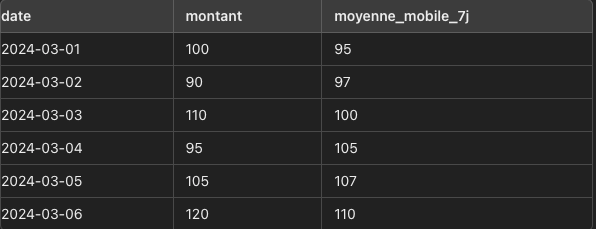
Par exemple, une entreprise de commerce électronique souhaite analyser les tendances de ses ventes quotidiennes pour ajuster ses stratégies de marketing et de stock. Plutôt que de se fier uniquement aux ventes quotidiennes, qui peuvent être très volatiles, l'entreprise décide d'utiliser une moyenne mobile pour lisser les données et obtenir une meilleure vue d'ensemble des tendances de vente.
Cette même société voudrait calculer la moyenne mobile sur 7 jours des ventes quotidiennes pour chaque produit afin de comprendre les tendances des ventes et identifier les périodes de haute ou basse performance.
Ce type de problème ne peut être résolu que par des window functions.
Windows functions
Une window function est une fonction dans SQL qui effectue des calculs sur un ensemble de lignes (appelé fenêtre) relié à la ligne courante, sans grouper les résultats en une seule ligne.
Lead
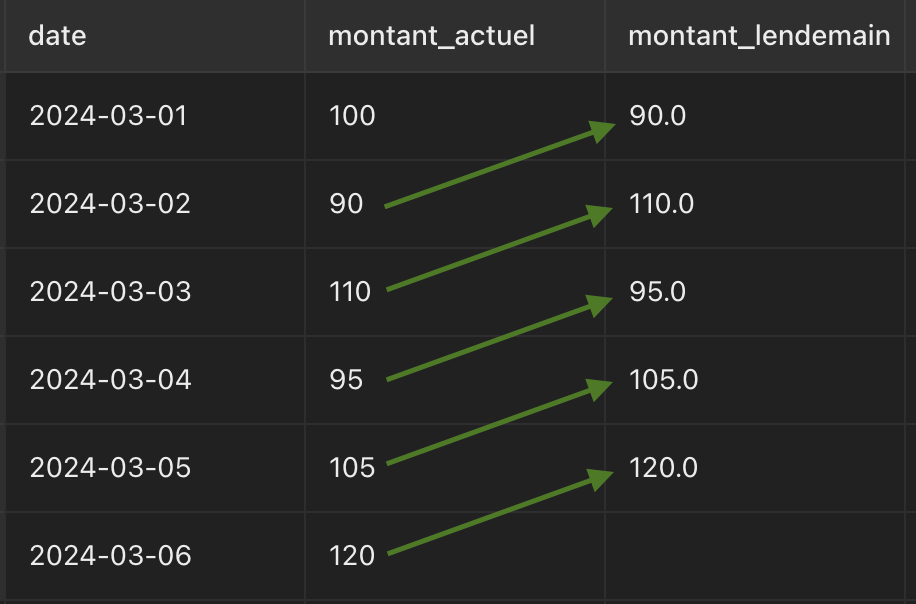
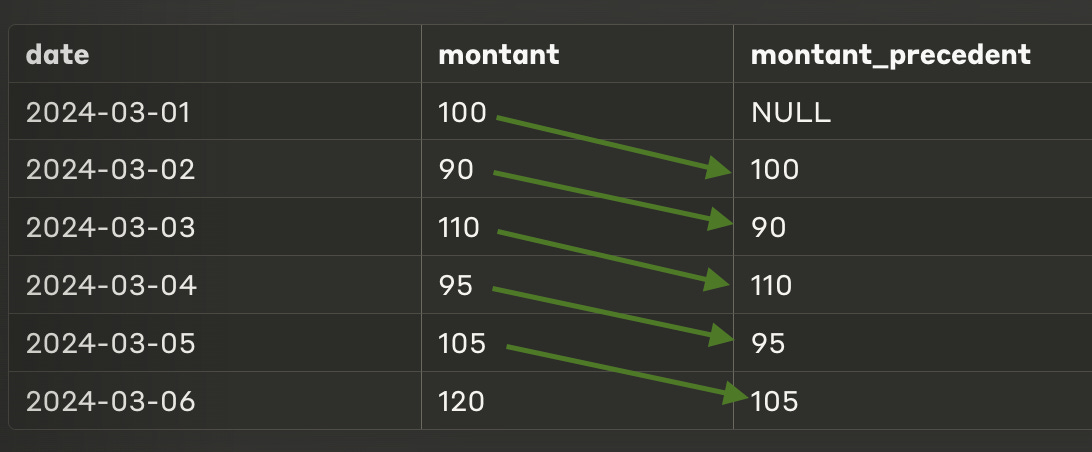
LEAD permet de capturer les valeurs suivantes par rapport à une ligne courante. On peut utiliser cette fonction pour comparer des valeurs d’un jour au lendemain, par exemple.
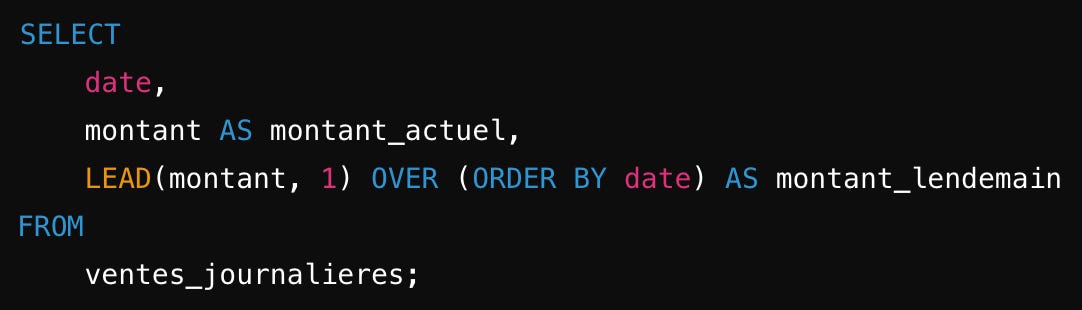
OVER : Permet de définir comment la window function doit examiner les lignes pour calculer la fonction d’agrégation.
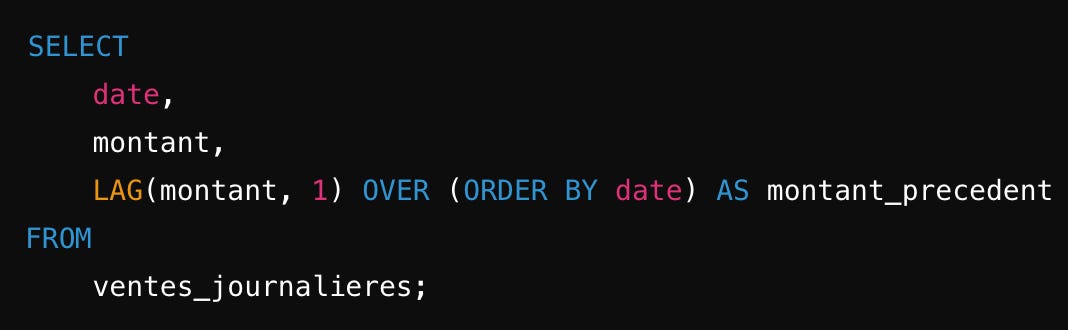
Lag
Fait la même chose que LEAD mais dans l’autre sens.
Row_number
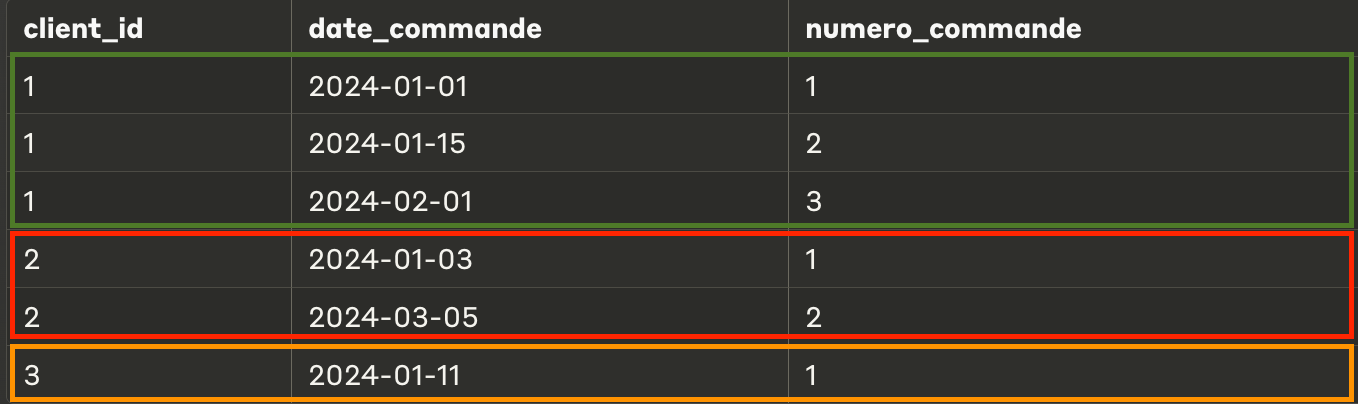
Cette commande permet de classer des valeurs ; cependant, si deux valeurs sont identiques, elles n'auront pas le même "rang", ce qui en fait l'une des meilleures options pour la déduplication.
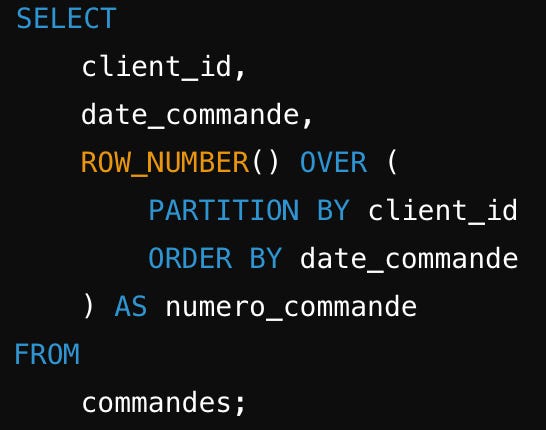
PARTITION BY : Définit la fenêtre, c'est-à-dire sur quelle plage appliquer ROW_NUMBER.
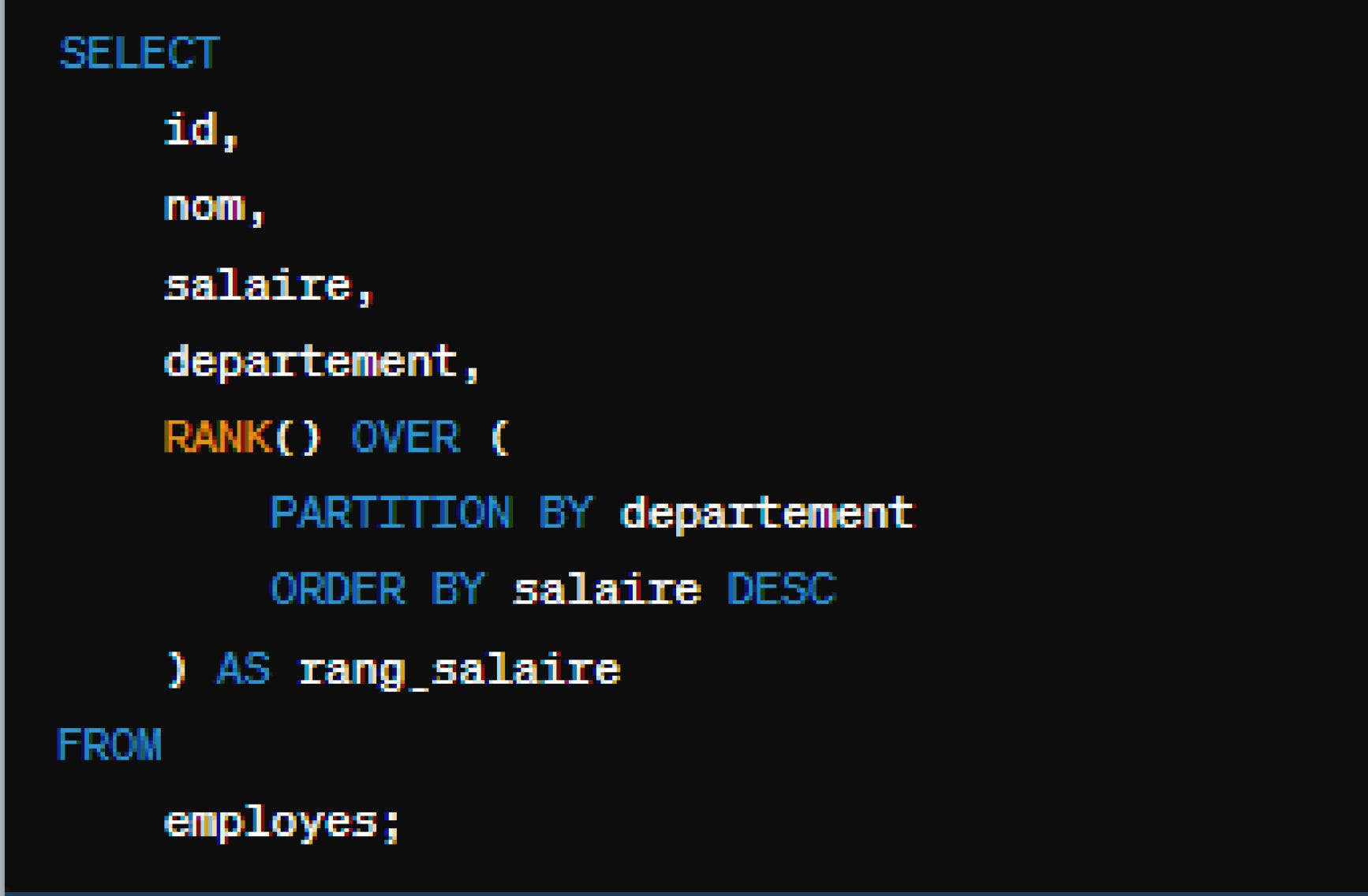
Rank
RANK va faire la même chose que ROW_NUMBER, à deux différences près :
Si deux valeurs sont égales, elles auront le même classement.
La valeur suivante aura un classement de N+1, même s'il y a plusieurs valeurs avec le même classement.
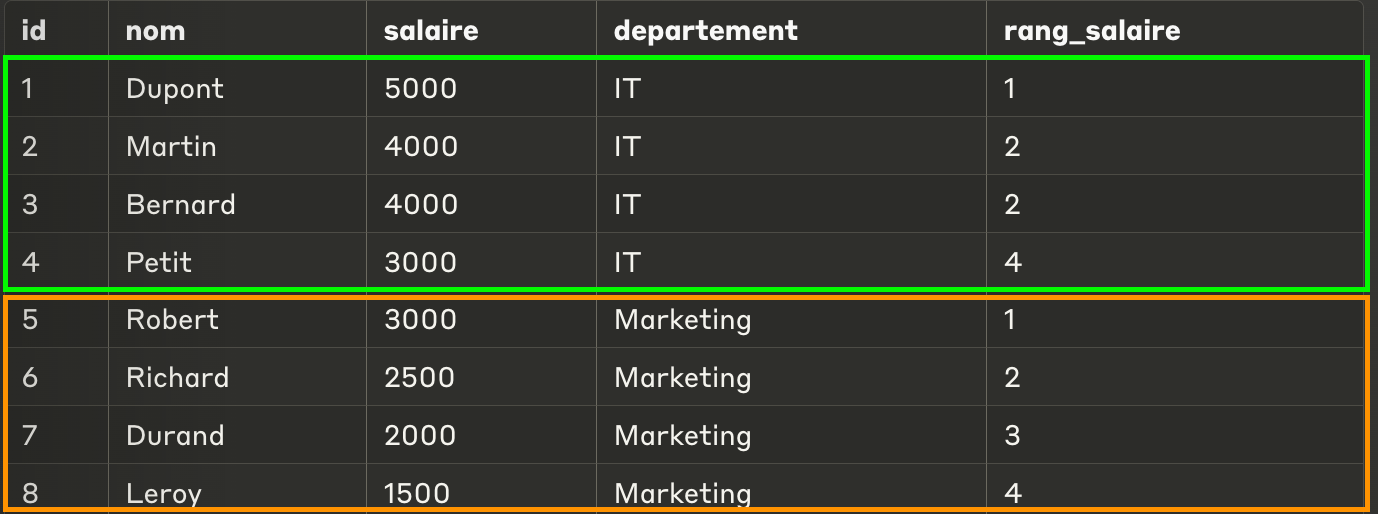
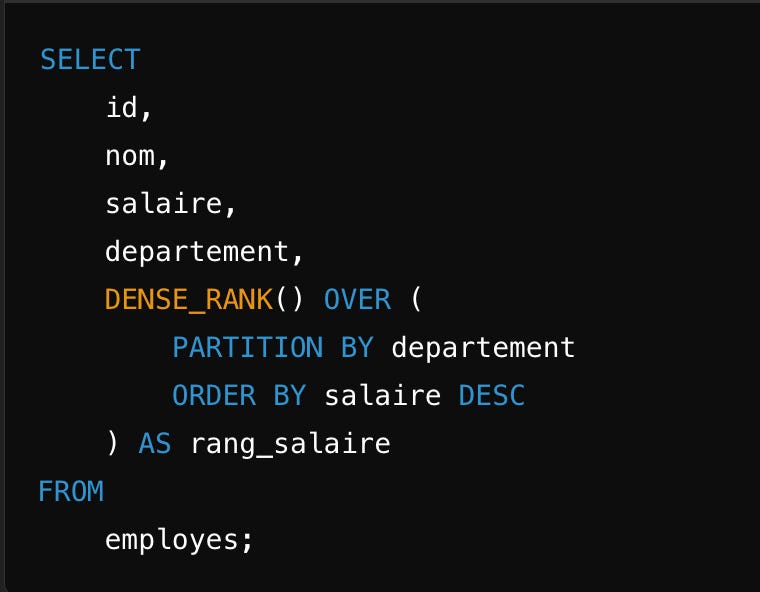
Dense_rank
DENSE_RANK est similaire à RANK, sauf qu’il ne saute pas de rang.
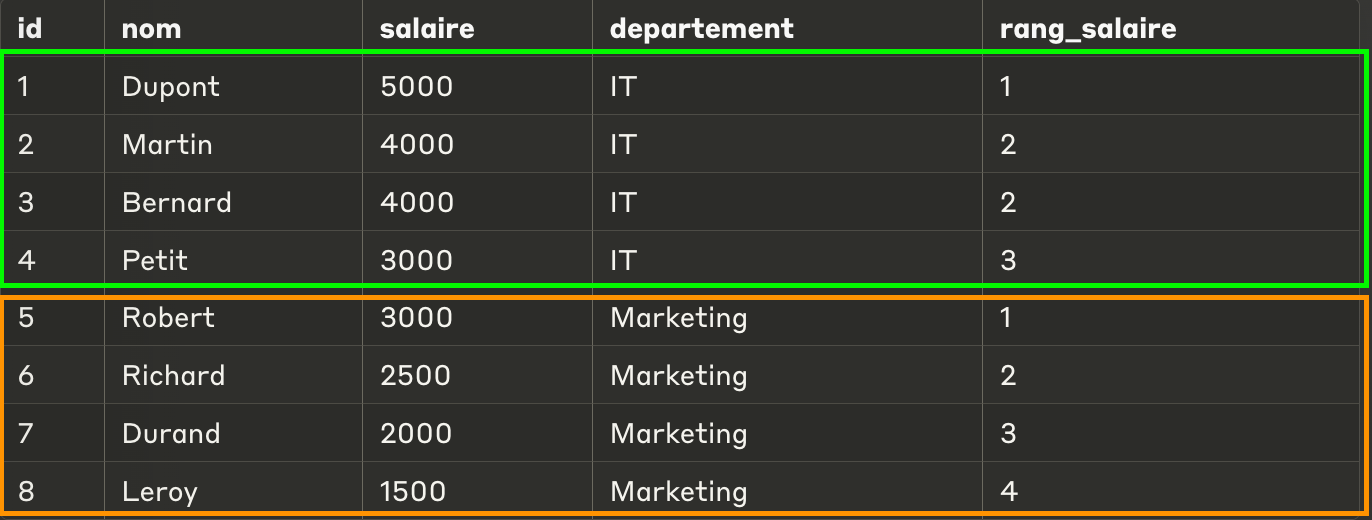
Moyenne mobile
La moyenne mobile consiste à faire une moyenne sur un ensemble de ligne (par exemple 3 ligne).
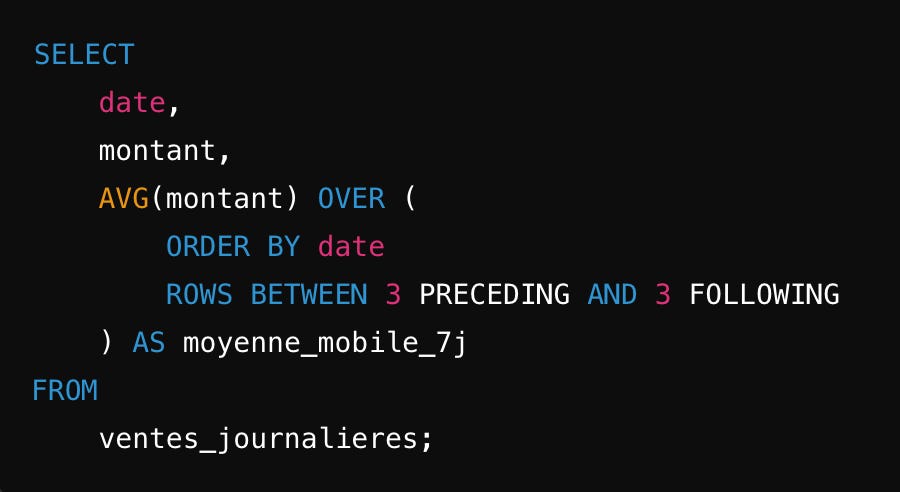
Détaillons la requête :
AVG : petit rappel au cas où, c’est le mot-clé pour la moyenne
OVER : Permet de la plage de ligne sur laquelle la moyenne mobile sera calculé
ROWS BETWEEN N PRECEDING AND M FOLLOWING : Permet de définir les ligne à prendre en considération pour calculer